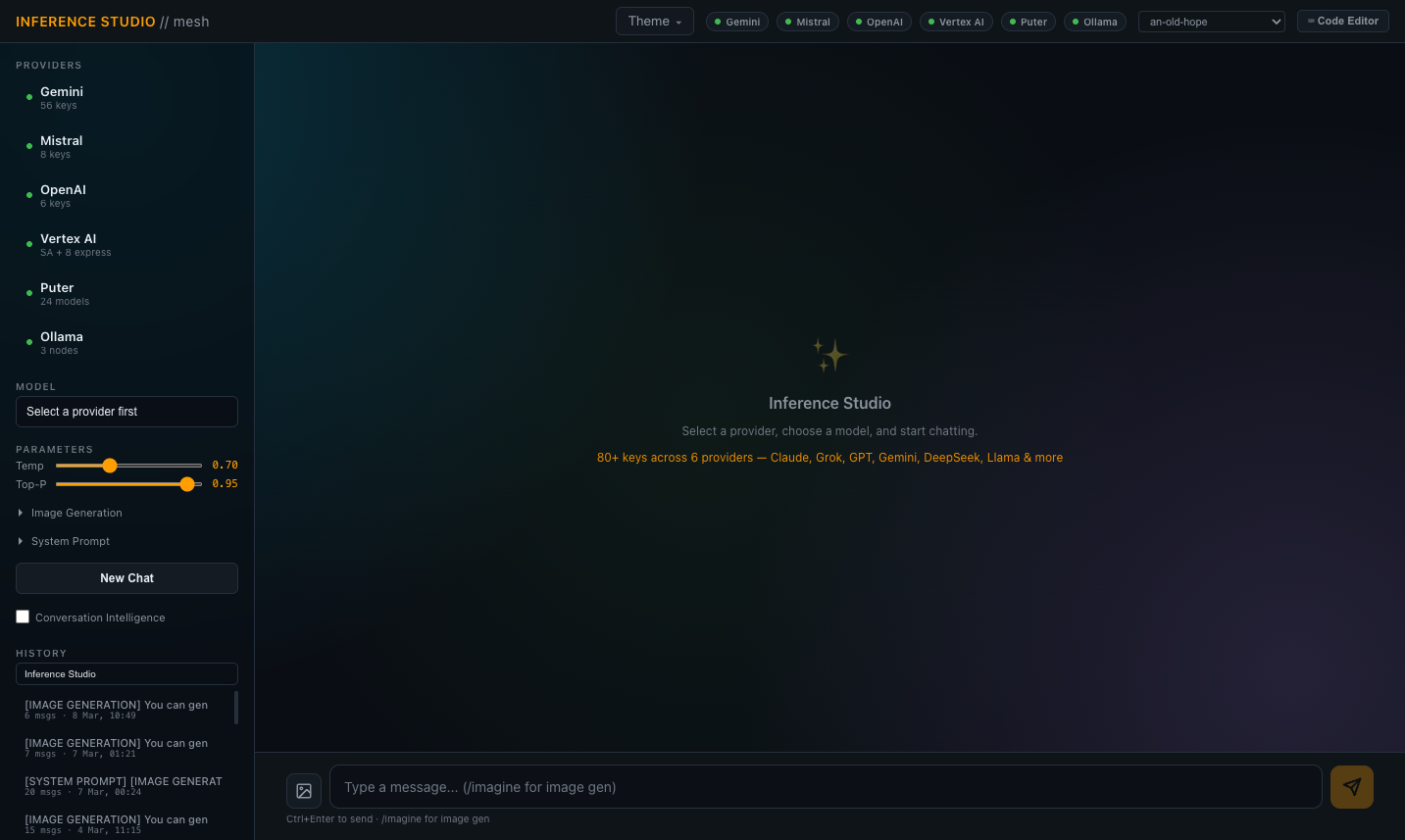
Unified AI Model Gateway
Centralised inference gateway routing requests across 6 providers and 146+ models through a single API endpoint. Cloud providers (Gemini, Vertex AI, Mistral, OpenAI) and a local inference runtime with 40+ models across multiple nodes — all accessible through one interface with consistent request/response formatting. No provider SDKs — all calls via raw HTTP for smaller footprint and easier debugging.
Two-tier rate limiting system. Per-key-per-model tracking enforces requests-per-minute delays and daily request caps with automatic midnight reset. Escalating 429 backoff: first rate limit triggers a 60-second cooldown, consecutive failures double it up to a 240-second cap, and successful responses clear the backoff immediately. Daily token budget enforcement with group-level caps for providers that meter by consumption rather than request count.
Round-robin key rotation across 80+ credential sets with automatic dead key detection — disabled keys are skipped without manual intervention. Cascading provider fallback: if one authentication method is exhausted, the system tries the next tier (e.g. Express keys before service account OAuth). Automatic model discovery runs nightly against provider APIs to detect newly available models and assign conservative rate limit defaults based on model tier.
Persistent conversation storage in PostgreSQL with per-message token tracking, provider/model/key attribution, and elapsed time logging. Supports both synchronous and streaming responses across all providers. Provider usage statistics tracked per key, per model, per time period — surfaced through a stats endpoint for monitoring consumption and identifying exhausted credentials.