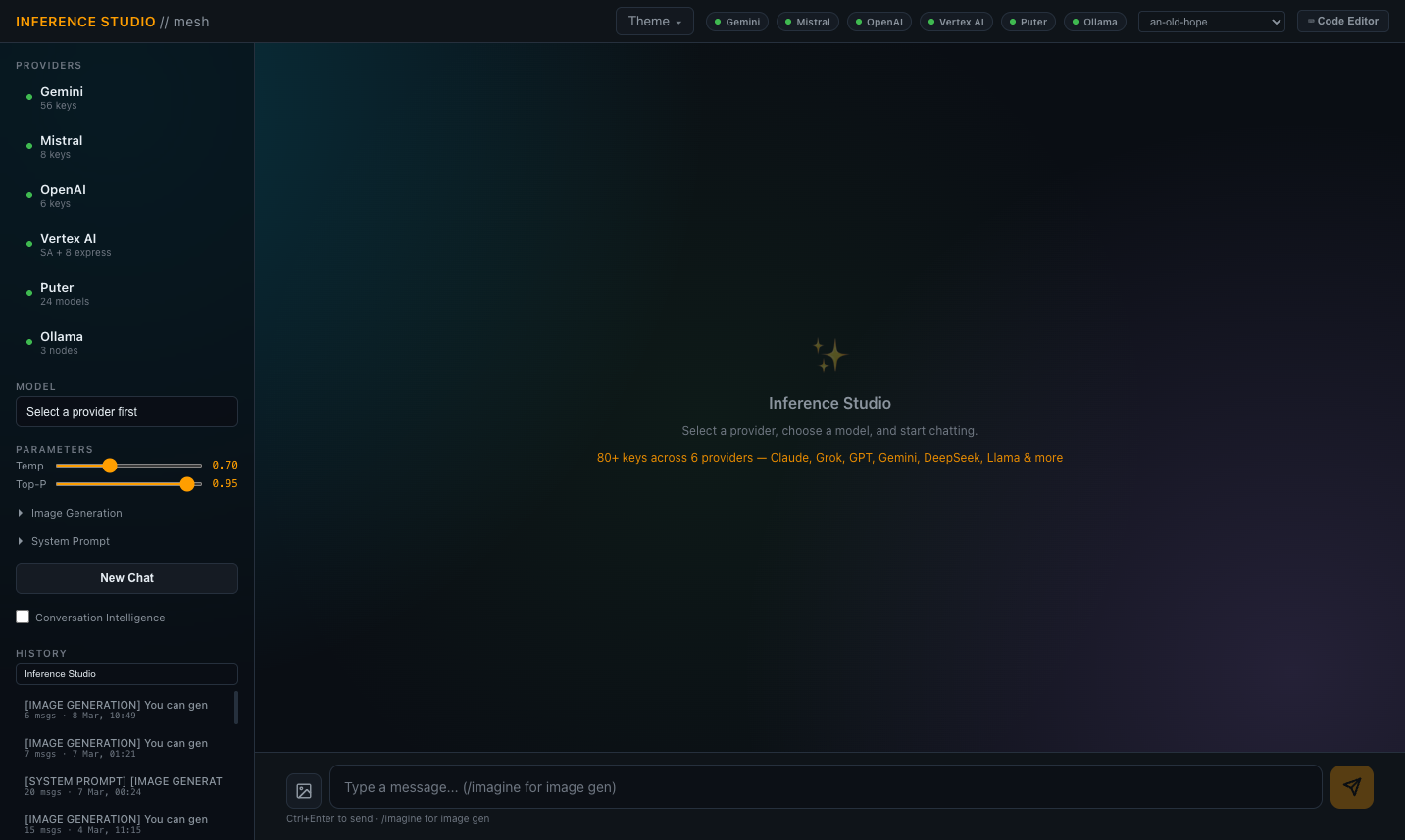
Multi-Provider Inference Studio
Chat interface spanning multiple LLM providers with seamless mid-conversation provider switching. Branch a conversation to a different model and continue with full context preserved — the same conversation history transfers across providers, so you can compare how different models handle identical context without re-prompting.
Supports cloud providers and local inference through one unified interface. Provider selection via dropdown, model selection filtered to the chosen provider's available models. Streaming responses via Server-Sent Events for real-time token output. Syntax highlighting for code blocks, markdown rendering for formatted responses, and conversation management with save/load/export.
Backed by the inference engine's key rotation and rate limiting — the chat interface doesn't manage credentials, it delegates to the gateway layer. Token counts and timing displayed per response. Conversation persistence to database with full message history, provider/model attribution per message, and session metadata.
Built for daily use as a working tool, not for benchmarking or evaluation. One interface to access any model from any provider — local 27B parameter models running on the mesh, cloud API models from multiple providers, and free-tier proxy models — without switching between provider dashboards or managing separate conversation histories.